
Designing Discover - Part 1
Wednesday, May 18, 2005
Three years ago, I was working on an insurance dispute involving several thousand pages of documents. I spent several weeks sorting, labeling, and duplicating invoices as well as recording the vital information from the invoice into an Excel spreadsheet. The work was tedious for me and expensive to the client (because it took so much time).
Of course, I had heard about the promise of a paperless office which I had never really paid attention to, but the concept was now starting to sound really good. Unfortunately, I couldn't find any software products that made economic sense for a managing few boxes of documents and that were less trouble to set up then doing the work by hand. To make a long story short, I quit my job, formed a new company, and locked myself in an office for two years to create such a program.
I decided to build a hosted solution, meaning that I would host the software, database, and scanned documents on my secure web servers and customers would access their documents and related tools through their web browser. Providing a hosted solution meant that I could get customers up in running in a very short amount of time. It also meant that smaller customers could get started for a much lower price than if I was selling "shrink-wrap" software to them.
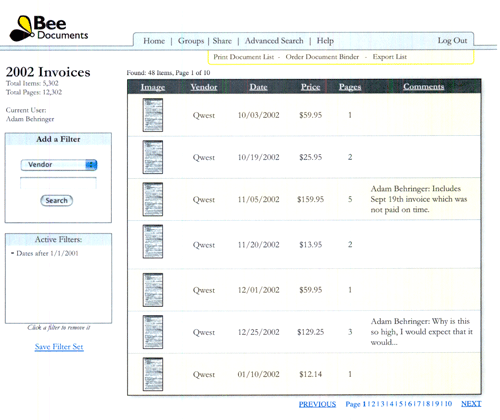
My first design of the document browser interface is shown in this screenshot (click it for a larger version). This user interface is pretty typical of database centric software. The pages are displayed in rows with the associated data in columns. The boxes on the left allow users to "filter" the results by building database queries. However common this interface is, it isn't a very good one for documents.
Tomorrow, I'll share the next revision of my interface design. Until then, think about the following question:
Why isn't a table based interface user friendly for managing scanned documents?
Labels: design, discover, document management
0 Comments:
Post a Comment
<< Home